





Egocentric Gesture Recognition for Head-Mounted AR devices
10th August 2018
Natural interaction with virtual objects in AR/VR environments makes for a smooth user experience. Gestures are a natural extension from real world to augmented space to achieve these interactions. Finding discriminating spatio-temporal features relevant to gestures and hands in ego-view is the primary challenge for recognising egocentric gestures. In this work we propose a data driven end-to-end deep learning approach to address the problem of egocentric gesture recognition, which combines an ego-hand encoder network to find ego-hand features, and a recurrent neural network to discern temporally discriminating features. Since deep learning networks are data intensive, we propose a novel data augmentation technique using green screen capture to alleviate the problem of ground truth annotation. In addition we publish a dataset of 10 gestures performed in a natural fashion in front of a green screen for training and the same 10 gestures performed in different natural scenes without green screen for validation. We also present the results of our network’s performance in comparison to the state-of-the-art using the AirGest dataset.
Green Screen Ego-Hand gesture Database
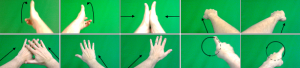
We defined a set of 10 basic gestures that use left, right and both hands. We collected gestures from 22 users, each repeated the gesture 3 times. Users performed the gesture in front of a green screen wearing HoloLens without any restrictions on the duration of each gesture, allowing them to express naturally. This resulted in a large variance in the duration per gesture and per user.
Network Architecture
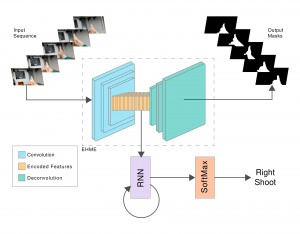
The idea of the new architecture is to find spatial feature maps specific to ego-hand gestures and to use these feature maps in a RNN to learn temporal discrimination for recognising ego-hand gestures, while keeping the network small. We achieve this by designing a two stage network architecture.The first stage is Ego-Hand Mask Encoder Network (EHME Net). EHME Net has an hourglass structure, with a series of convolution filters of increasing depth and decreasing height and width, until they are sufficiently small. Then, we suffix the network with deconvolution filters with decreasing depth and increasing height and width until they reach the size of the mask. Finally, we use the feature maps near the neck of the hourglass as an input to an LSTM network to classify the sequence of encoded features.
Links