





Towards Audio-Visual Saliency Prediction for Omnidirectional Video with Spatial Audio
7th December 2021Abstract
Omnidirectional videos (ODVs) with spatial audio enable viewers to perceive 360° directions of audio and visual signals during the consumption of ODVs with head-mounted displays (HMDs). By predicting salient audio-visual regions, ODV systems can be optimized to provide an immersive sensation of audio-visual stimuli with high-quality. Despite the intense recent effort for ODV saliency prediction, the current literature still does not consider the impact of auditory information in ODVs. In this work, we propose an audio-visual saliency (AVS360) model that incorporates 360° spatial-temporal visual representation and spatial auditory information in ODVs. The proposed AVS360model is composed of two 3D residual networks (ResNets) to encode visual and audio cues. The first one is embedded with a spherical representation technique to extract 360° visual features, and the second one extracts the features of audio using the log mel-spectrogram. We emphasize sound source locations by integrating audio energy map (AEM) generated from spatial audio description (i.e., ambisonics) and equator viewing behavior with equator center bias (ECB). The audio and visual features are combined and fused with AEM and ECB via attention mechanism. Our experimental results show that the AVS360 model has significant superiority over five state-of-the-art saliency models. To the best of our knowledge, it is the first work that develops the audio-visual saliency model in ODVs. The code is publicly available at: https://github.com/FannyChao/AVS360_audiovisual_saliency_360.
Architecture
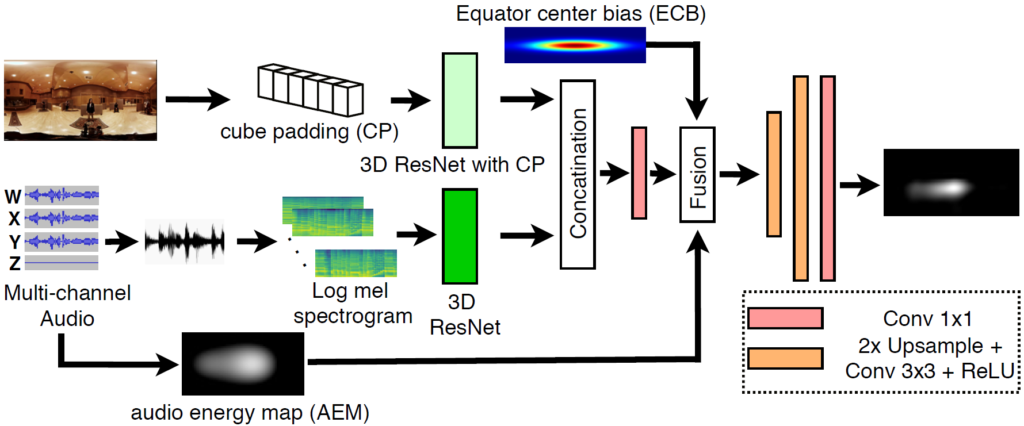
The overall diagram of the proposed AVS360 model is illustrated in Fig. 1. The proposed model is an end-to-end 2-stream structure composed of two 3D ResNets to separately extract spatial-temporal visual and audio cues in ODV. A fusion network is appended after embedding of audio-visual features. The embedded features are then enhanced with the information of spatial audio (i.e., ambisonics) and user navigation tendency (i.e., ECB), and decoded into a saliency map.
Experiment Results
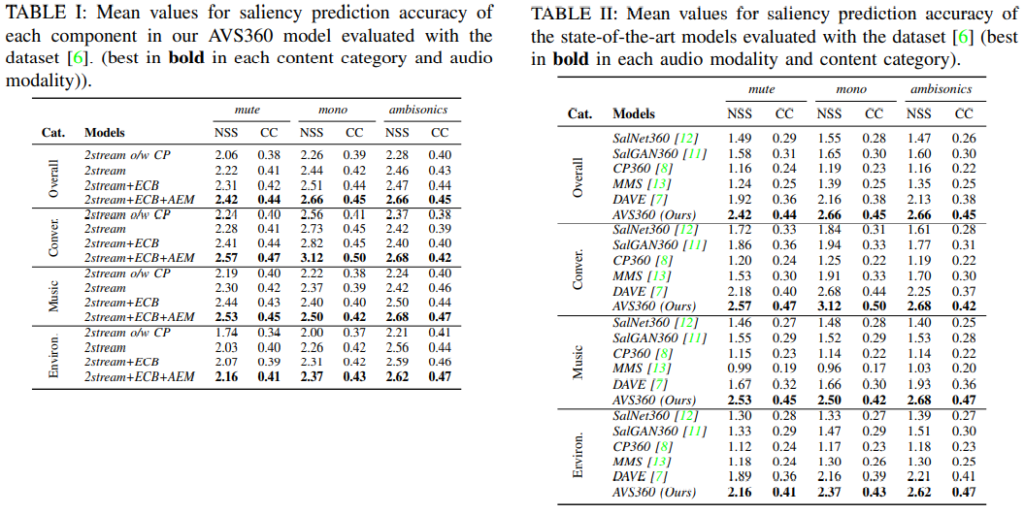
Table II shows the accuracy of our proposed AVS360 model and other five state-of-the-art models evaluated on the
test dataset. SalGAN360 and SalNet360 are visual saliency prediction for ODIs, CP360 is visual saliency prediction for ODVs, while MMS and DAVE are audio-visual saliency prediction for 2D videos. We can see from the results that our model significantly outperforms the others in overall ODVs and every content category in all three audio modalities. To our surprise, even in mute modality, our model, which takes account of spatial auditory information, surpasses a significant margin over the models, only taking account of visual information. The results show that using AEM as an input feature can improve the saliency prediction models for ODV.
Publication
Towards Audio-Visual Saliency Prediction for Omnidirectional Video with Spatial Audio
Fang-Yi Chao, Cagri Ozcinar, Lu Zhang, Wassim Hamidouch, Olivier Deforges, Aljosa Smolic, 2020 IEEE International Conference on Visual Communications and Image Processing (VCIP)