





CatNet: Class Incremental 3D ConvNets for Lifelong Egocentric Gesture Recognition
23rd December 2020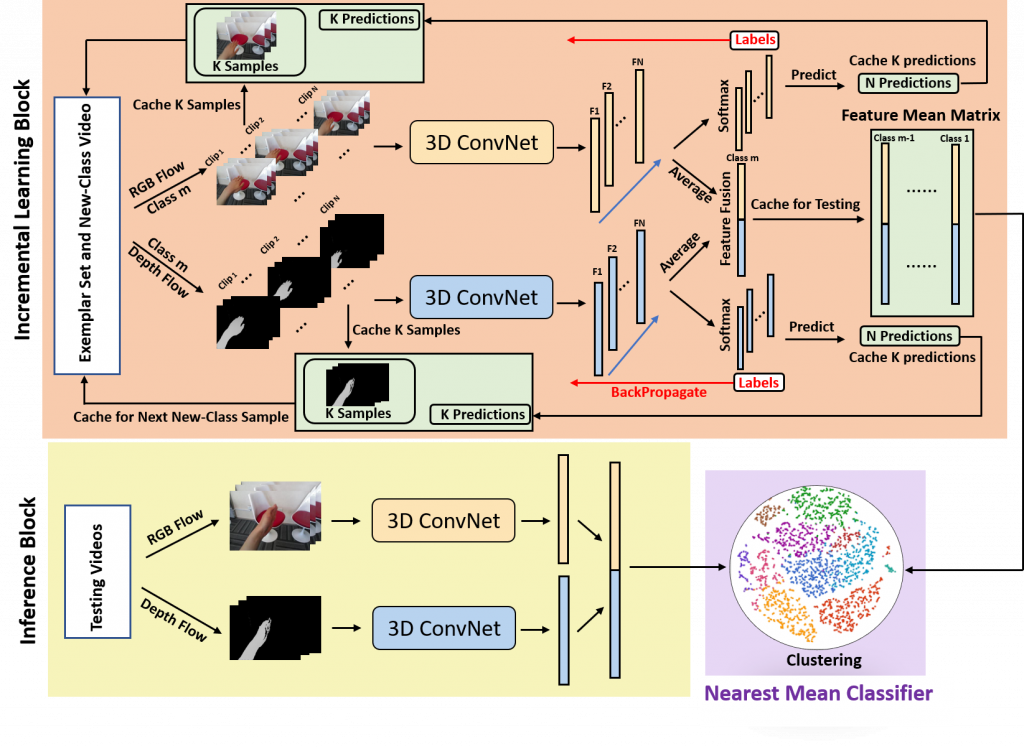
Abstract
Egocentric gestures are the most natural form of communication for humans to interact with wearable devices such as VR/AR helmets and glasses. A major issue in such scenarios for real-world applications is that may easily become necessary to add new gestures to the system e.g., a proper VR system should allow users to customize gestures incrementally. Traditional deep learning methods require storing all previous class samples in the system and training the model again from scratch by incorporating previous samples and new samples, which costs humongous memory and significantly increases computation over time. In this work, we demonstrate a lifelong 3D convolutional framework – c(C)la(a)ss increment(t)al net(Net)works (CatNet), which considers temporal information in videos and enables lifelong learning for egocentric gesture video recognition by learning the feature representation of an exemplar set selected from previous class samples. Importantly, we propose a two-stream CatNet, which deploys RGB and depth modalities to train two separate networks. We evaluate CatNets on a publicly available dataset – EgoGesture dataset, and show that CatNets can learn many classes incrementally over a long period of time. Results also demonstrate that the two-stream architecture achieves the best performance on both joint training and class incremental training compared to 3 other one-stream architectures. The codes and pre-trained models used in this work are provided at here.
This paper is published at CVPR workshop 2020