





Light Field Saliency Estimation
13th April 2021
Light fields have become a major research topic in recent years. Even though there are now efforts in different applications such as compression, display, and post-processing, the human visual perception for light fields is rarely studied. In this project, we study automatic visual attention estimation for light fields. This webpage provides additional results which could not be placed within our papers due to space constraints.
This page is dedicated to our automatic light field saliency estimation works. Please refer to Visual Attention for Light Fields webpage for the ground truth visual attention collection.
Related Publications:
- A. Gill, E. Zerman, M. Alain, M. Le Pendu, A. Smolic. “Focus Guided Light Field Saliency Estimation” Thirteenth International Conference on Quality of Multimedia Experience (QoMEX). IEEE, 2021.
@inproceedings{gill2021focus,
title = {Focus Guided Light Field Saliency Estimation},
author = {Ailbhe Gill and Emin Zerman and Martin Alain and Le Pendu, Mikael and Aljosa Smolic},
year = {2021},
booktitle = {Thirteenth International Conference on Quality of Multimedia Experience (QoMEX)},
}
Additional Results
Due to the page limit of the venue to which we submitted our work, we could not provide all the results in the manuscript. Here we will share additional results for our study.
The data we used were from 4 different databases: Stanford1, EPFL2, HCI Heidelberg3.
|
|
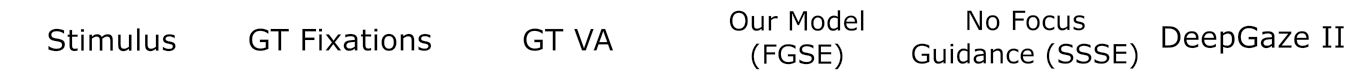 |
|
|
Boardgames3 |
Region1 |
 |
|
Boardgames3 |
Region2 |
 |
|
Dino3 |
Region1 |
 |
|
Dino3 |
Region2 |
 |
|
Dishes3 |
Region1 |
 |
|
Dishes3 |
Region2 |
 |
|
Friends2 |
Region1 |
 |
|
Friends2 |
Region2 |
 |
|
LegoKnights1 |
Region1 |
 |
|
LegoKnights1 |
Region2 |
 |
|
Medieval3 |
Region1 |
 |
|
Medieval3 |
Region2 |
 |
|
Pens3 |
Region1 |
 |
|
Pens3 |
Region2 |
 |
|
Platonic3 |
Region1 |
 |
|
Platonic3 |
Region2 |
 |
|
Sideboard3 |
Region1 |
 |
|
Sideboard3 |
Region2 |
 |
|
Table3 |
Region1 |
 |
|
Table3 |
Region2 |
 |
|
Tarot-Large1 |
Region1 |
 |
|
Tarot-Large1 |
Region2 |
 |
|
Tarot-Small1 |
Region1 |
 |
|
Tarot-Small1 |
Region2 |
 |
|
Tower3 |
Region1 |
 |
|
Tower3 |
Region2 |
 |
|
Town3 |
Region1 |
 |
|
Town3 |
Region2 |
 |
|
Treasure1 |
Region1 |
 |
|
Treasure1 |
Region2 |
 |
|
Vespa2 |
Region1 |
 |
|
Vespa2 |
Region2 |
 |
|
Vinyl3 |
Region1 |
 |
|
Vinyl3 |
Region2 |
 |
Acknowledgement
This publication has emanated from research conducted with the financial support of Science Foundation Ireland (SFI) under the Grant Number 15/RP/2776.
Contact
If you have any question, send an e-mail to gilla3@tcd.ie or zermane@tcd.ie or alainm@tcd.ie.