





Deep Learning for Visual Computing


A Geometry-Sensitive Approach for Photographic Style Classification
Abstract Photographs are characterized by different compositional attributes like the Rule of Thirds, depth of field, vanishing-lines etc. The presence or absence of one or more of these attributes contributes ...
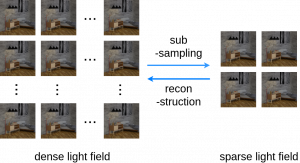
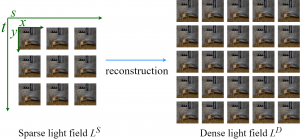
A Study of Efficient Light Field Subsampling and Reconstruction Strategies
Abstract Limited angular resolution is one of the main obstacles for practical applications of light fields. Although numerous approaches have been proposed to enhance angular resolution, view selection strategies have ...
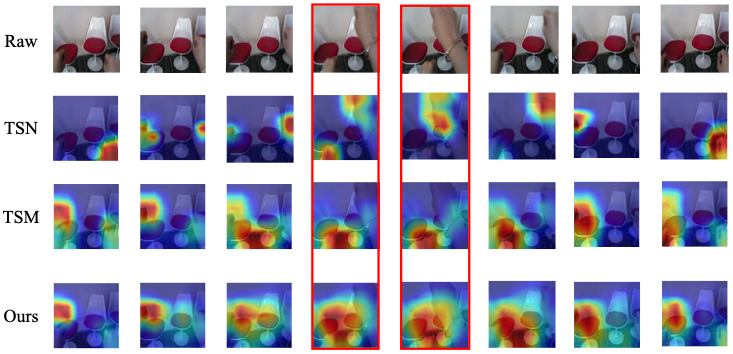
ACTION-Net: Multipath Excitation for Action Recognition (CVPR 2021)
Spatial-temporal, channel-wise, and motion patterns are three complementary and crucial types of information for video action recognition. Conventional 2D CNNs are computationally cheap but cannot catch temporal relationships; 3D CNNs ...

Aesthetic Image Captioning from Weakly-Labelled Photographs
Abstract Aesthetic image captioning (AIC) refers to the multi-modal task of generating critical textual feedbacks for photographs. While in natural image captioning (NIC), deep models are trained in an end-to-end ...

AlphaGAN: Generative adversarial networks for natural image matting
Abstract We present the first generative adversarial network (GAN) for natural image matting. Our novel generator network is trained to predict visually appealing alphas with the addition of the adversarial ...

Augmenting Hand-Drawn Art with Global Illumination Effects through Surface Inflation
Abstract We present a method for augmenting hand-drawn characters and creatures with global illumination effects. Given a single view drawing only, we use a novel CNN to predict a high-quality ...
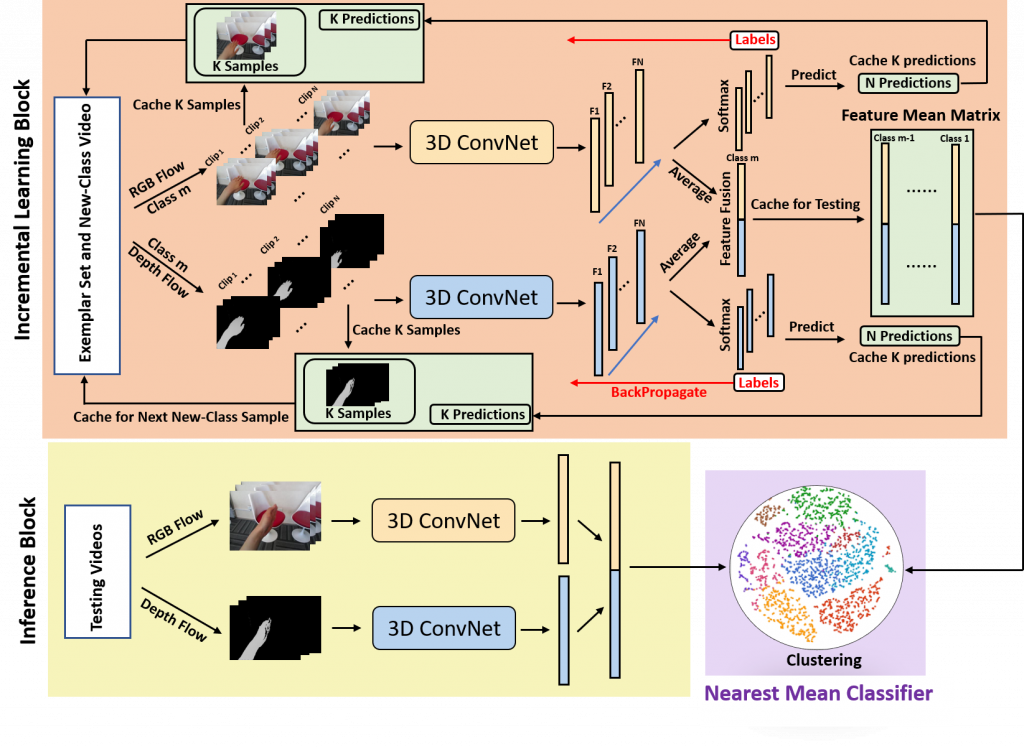
CatNet: Class Incremental 3D ConvNets for Lifelong Egocentric Gesture Recognition
Abstract Egocentric gestures are the most natural form of communication for humans to interact with wearable devices such as VR/AR helmets and glasses. A major issue in such scenarios for ...
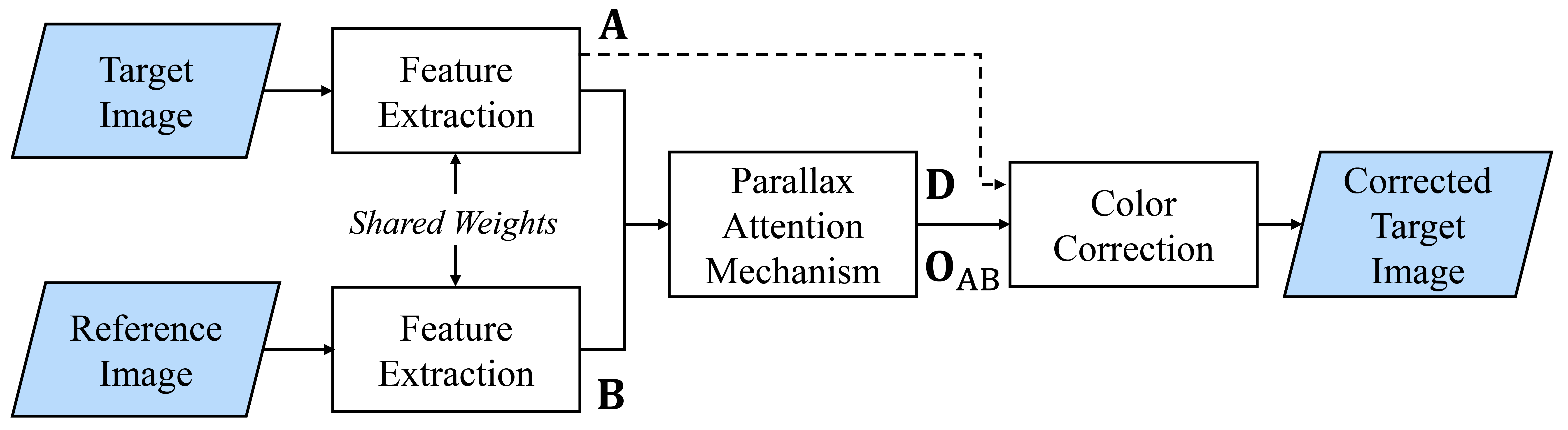
Color Mismatch Correction
This webpage is dedicated to the publications about color mismatch correction in stereoscopic 3D (S3D) images and videos. Here, you can find the publications and the related publicly available material ...

ColorNet: Estimating colorfulness in natural images
This page contains related materials for learning-based colorfulness estimation. ABSTRACT Measuring the colorfulness of a natural or virtual scene is critical for many applications in image processing field ranging from ...

Deep Convolutional Neural Networks for estimating lens distortion parameters
Abstract In this paper we present a convolutional neural network (CNN) to predict multiple lens distortion parameters from a single input image. Unlike other methods, our network is suitable to ...
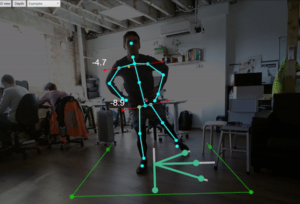
Deep Learning for Quality Assessment of Physiotherapy Rehab Exercises
Proposed by Richard BlythmanEmail: blythmar(at)tcd.ie Tele-health is fast becoming more popular and physiotherapy sessions are often undertaken during live video streaming sessions. Smart video analysis using deep learning models (such ...

Deep Normal Estimation for Automatic Shading of Hand-Drawn Characters
In this paper we present a new fully automatic pipeline for generating shading effects on hand-drawn characters. Our method takes as input a single digitized sketch of any resolution and ...

Deep Tone Mapping Operator for High Dynamic Range Images
Abstract A computationally fast tone mapping operator (TMO) that can quickly adapt to a wide spectrum of high dynamic range (HDR) content is quintessential for visualization on varied low dynamic ...
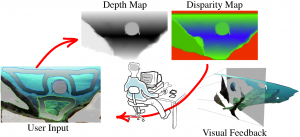
DeepStereoBrush: Interactive Depth Map Creation
In this paper, we introduce a novel interactive depth map creation approach for image sequences which uses depth scribbles as input at user-defined keyframes. These scribbled depth values are then ...
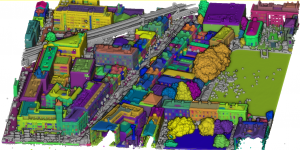
DublinCity Dataset
Please click the image or here DublinCity Dataset to access the dataset! ...
Egocentric Gesture Recognition for Head-Mounted AR devices
Natural interaction with virtual objects in AR/VR environments makes for a smooth user experience. Gestures are a natural extension from real world to augmented space to achieve these interactions. Finding ...

Foreground color prediction through inverse compositing
Abstract In natural image matting, the goal is to estimate the opacity of the foreground object in the image. This opacity controls the way the foreground and background is blended ...
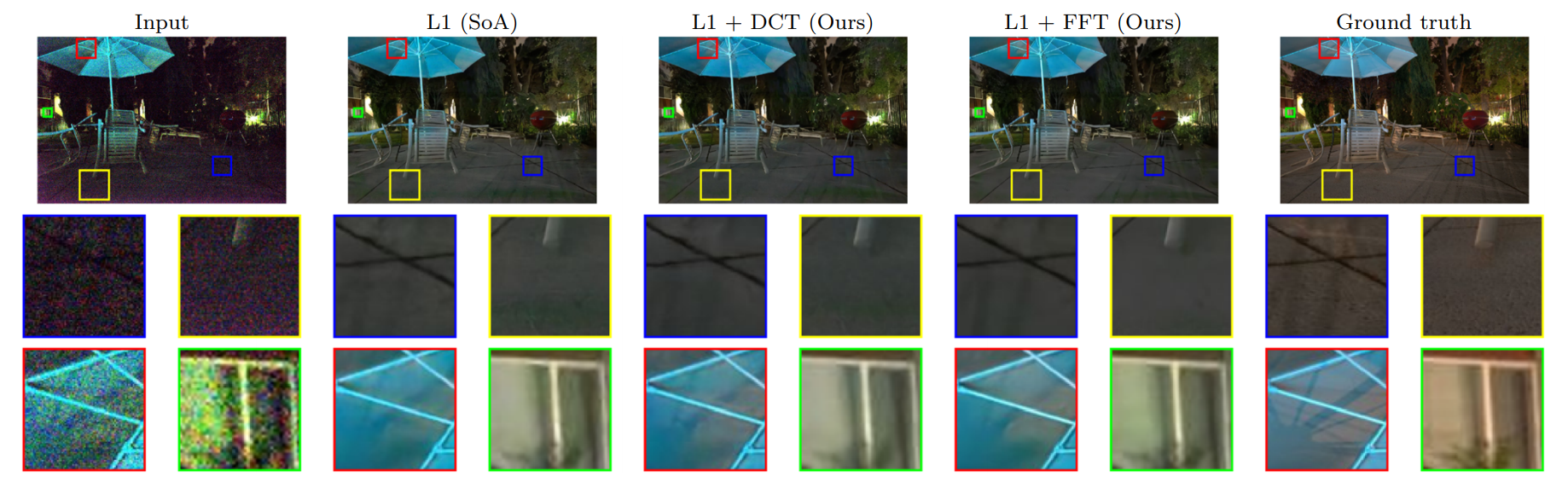
Frequency-domain loss function for deep exposure correction of dark images
Abstract We address the problem of exposure correction of dark, blurry and noisy images captured in low-light conditions in the wild. Classical image-denoising filters work well in the frequency space ...

Light Field Style Transfer With Local Angular Consistency
Abstract Style transfer involves combining the style of one image with the content of another to form a new image. Unlike traditional two-dimensional images which only capture the spatial intensity ...

LineArt dataset
As part of our paper Augmenting Hand-Drawn Art with Global Illumination Effects through Surface Inflation, we release a high-resolution LineArt dataset of line drawings with corresponding ground-truth normal and depth ...

SalNet360: Saliency Maps for omni-directional images with CNN
Abstract The prediction of Visual Attention data from any kind of media is of valuable use to content creators and used to efficiently drive encoding algorithms. With the current trend ...
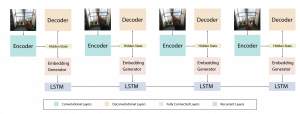
Self-supervised light field view synthesis using cycle consistency
Abstract High angular resolution is advantageous for practical applications of light fields. In order to enhance the angular resolution of light fields, view synthesis methods can be utilized to generate ...
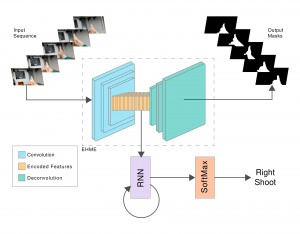
Simultaneous Segmentation and Recognition: Towards more accurate Ego Gesture Recognition
Ego hand gestures can be used as an interface in AR and VR environments. While the context of an image is important for tasks like scene understanding, object recognition, image ...
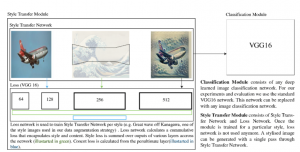
STaDA: Style Transfer as Data Augmentation
Abstract The success of training deep Convolutional Neural Networks (CNNs) heavily depends on a significant amount of labelled data. Recent research has found that neural style transfer algorithms can apply ...

Super-resolution of Omnidirectional Images Using Adversarial Learning
Abstract An omnidirectional image (ODI) enables viewers to look in every direction from a fixed point through a headmounted display providing an immersive experience compared to that of a standard ...
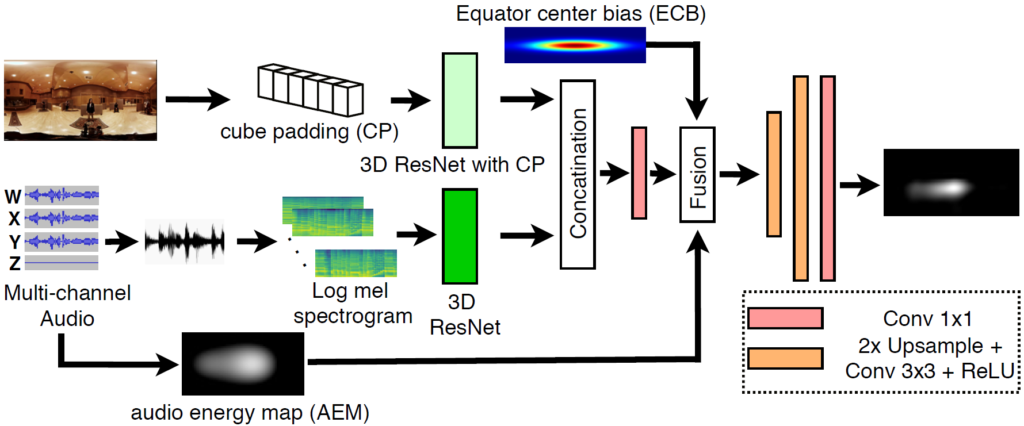
Towards Audio-Visual Saliency Prediction for Omnidirectional Video with Spatial Audio
Abstract Omnidirectional videos (ODVs) with spatial audio enable viewers to perceive 360° directions of audio and visual signals during the consumption of ODVs with head-mounted displays (HMDs). By predicting salient ...
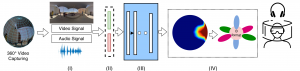
Towards generating ambisonics using audio-visual cue for virtual reality
Abstract Ambisonics i.e., a full-sphere surround sound, is quintessential with 360-degree visual content to provide a realistic virtual reality (VR) experience. While 360-degree visual content capture gained a tremendous boost ...
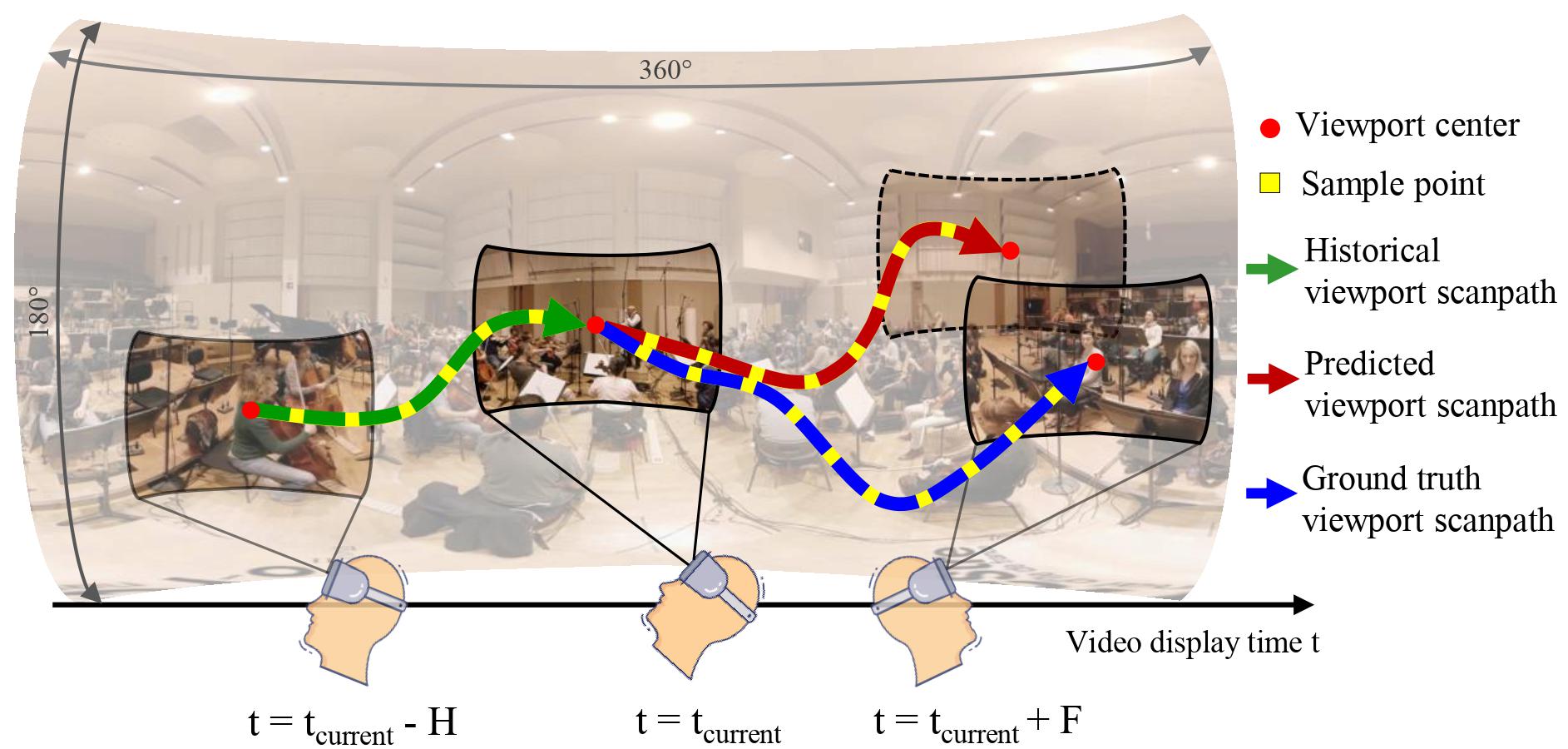
Transformer-based Long-Term Viewport Prediction in 360° Video: Scanpath is All You Need
Fig. 1: Illustration of viewport prediction in 360° video. Our model aims to predict the viewport scanpath in the forthcoming F seconds given the past H-second viewport scanpath. Abstract Virtual ...
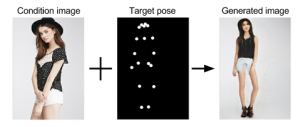
Using GANs to Synthesize Videos of Physiotherapy Rehab Exercises from Motion Capture Data
Proposed by Richard BlythmanEmail: blythmar(at)tcd.ie Motion capture systems are often used to capture ground truth 3D pose labels in combination with RGB videos for training deep computer vision models for ...
Using LSTM for Automatic Classification of Human Motion Capture Data
Creative studios tend to produce an overwhelming amount of content everyday and being able to manage these data and reuse it in new productions represent a way for reducing costs ...