ACTION-Net: Multipath Excitation for Action Recognition (CVPR 2021)
11th March 2021Spatial-temporal, channel-wise, and motion patterns are three complementary and crucial types of information for video action recognition. Conventional 2D CNNs are computationally cheap but cannot catch temporal relationships; 3D CNNs can achieve good performance but are computationally intensive. In this work, we tackle this dilemma by designing a generic and effective module that can be embedded into 2D CNNs. To this end, we propose a spAtio-temporal, Channel and moTion excitatION (ACTION) module consisting of three paths: Spatio-Temporal Excitation (STE) path, Channel Excitation (CE) path, and Motion Excitation (ME) path. The STE path employs one channel 3D convolution to characterize spatio-temporal representation. The CE path adaptively recalibrates channel-wise feature responses by explicitly modeling interdependencies between channels in terms of the temporal aspect. The ME path calculates feature-level temporal differences, which is then utilized to excite motion-sensitive channels. We equip 2D CNNs with the proposed ACTION module to form a simple yet effective ACTION-Net with very limited extra computational cost. ACTION-Net is demonstrated by consistently outperforming 2D CNN counterparts on three backbones (i.e., ResNet-50, MobileNet V2 and BNInception) employing three datasets (i.e., Something-Something V2, Jester, and EgoGesture). Codes are available at https://github.com/V-Sense/ACTION-Net.
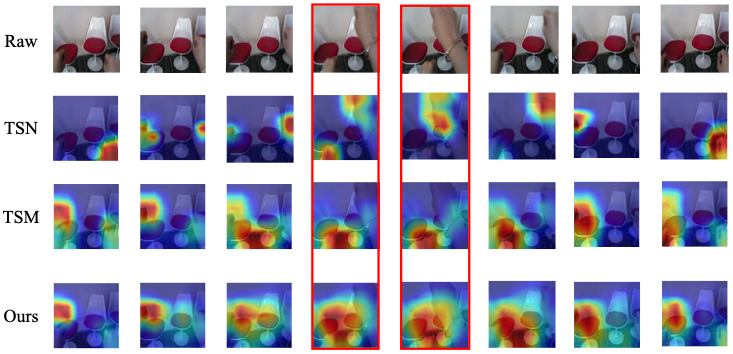
Three Attention Mechanisms
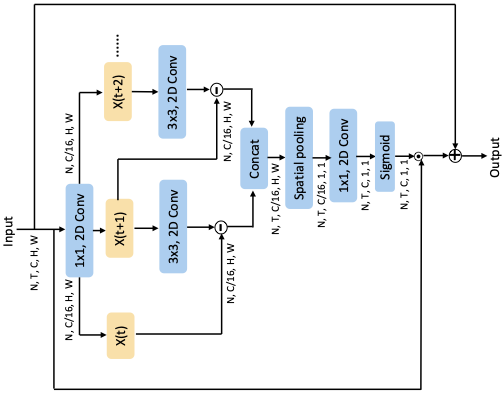
The ACTION module basically contains three excitation paths: Spatial-Temporal Excitation (STE), Channel Excitation (CE) and Motion Excitation (ME).
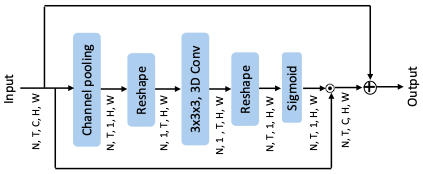
STE: STE is efficiently designed for exciting spatio-temporal information by utilizing 3D convolution. Unlike the traditional 3D convolutional, we first average all channels to get a global spatio-temporal feature, which is able to significantly reduce the computation for 3D convolution. The output of STE contains global spatio-temporal information.
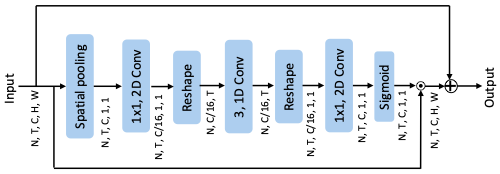
CE: CE is proposed beyond the SE-Net for activating the channel interdependencies regarding the temporal information. We add 1D temporal convolution to the SE-Net between the squeeze and unsqueeze operation. The output contains channel interdependencies based on the temporal perspective.
ME: ME has been deployed by previous methods such as STM and TEA. It shows the efficacy of reasoning action movement in the video. The ME model the difference between adjacent frames in the feature level. We combine the ME with excited sources introduced above for reasoning rich information maintained in the video.
ACTION Module
The overall ACTION module takes the element-wise addition of three excited features generated by STE, CE andME respectively. By doing this, the output of the ACTION module can perceiveinformation from a spatio-temporal perspective, channel interdependencies and motion.
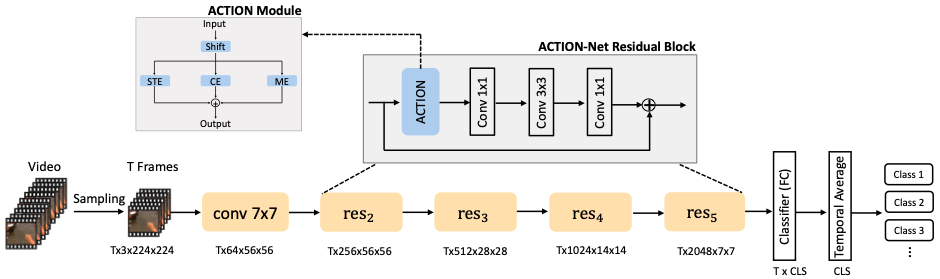
Experiment
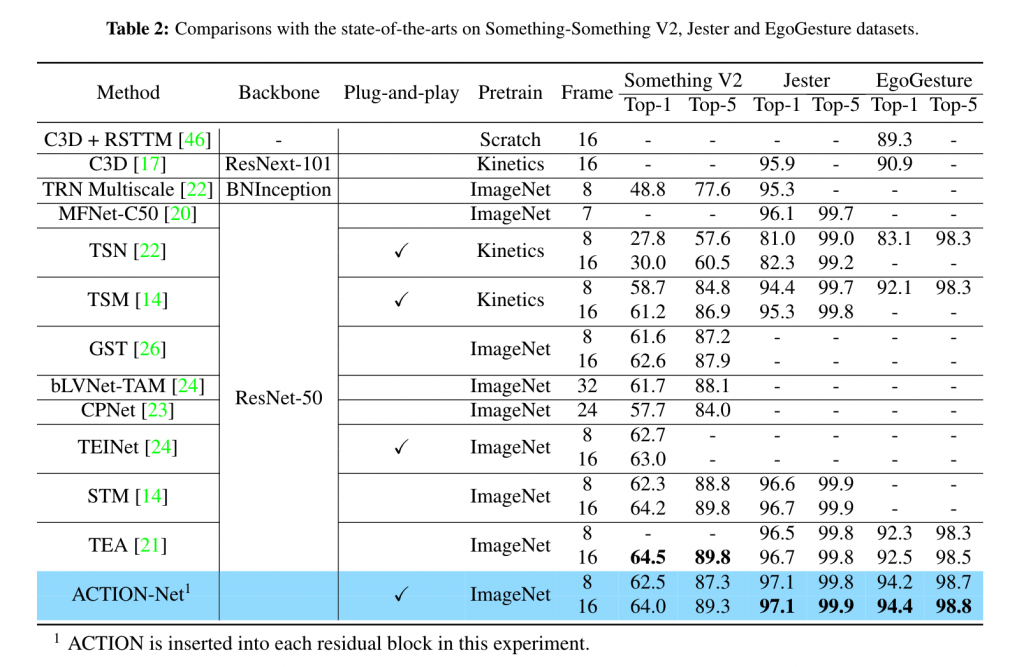
Comparison to the state-of-the-art
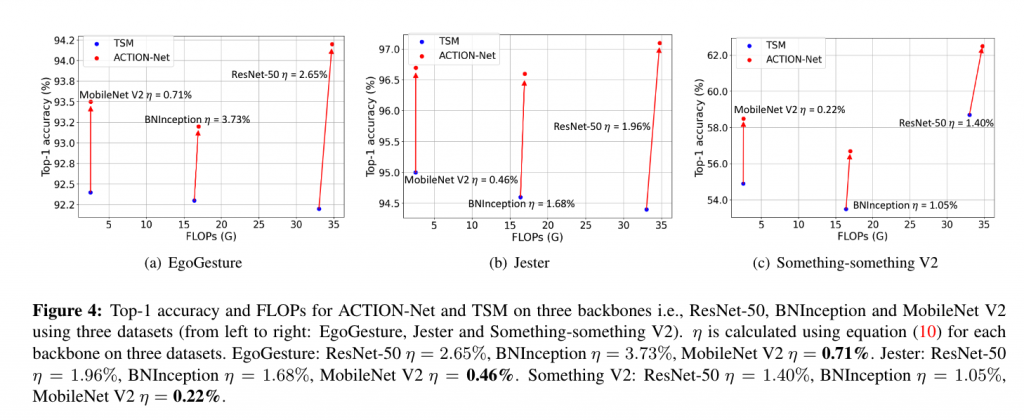
Our ACTION-Net outperforms the prevsious literature for EgoGesture and Jester. It also achieves the competive performance on Something-Something V2 comparing to STM and TEA. It is worh nothing that STM and TEA are specifically designed for ResNet and Res2Net. Thus our ACTION enjoys flexibly being equipped by other architecture such as MobileNet V2 and BNInception that we investigated in this study.
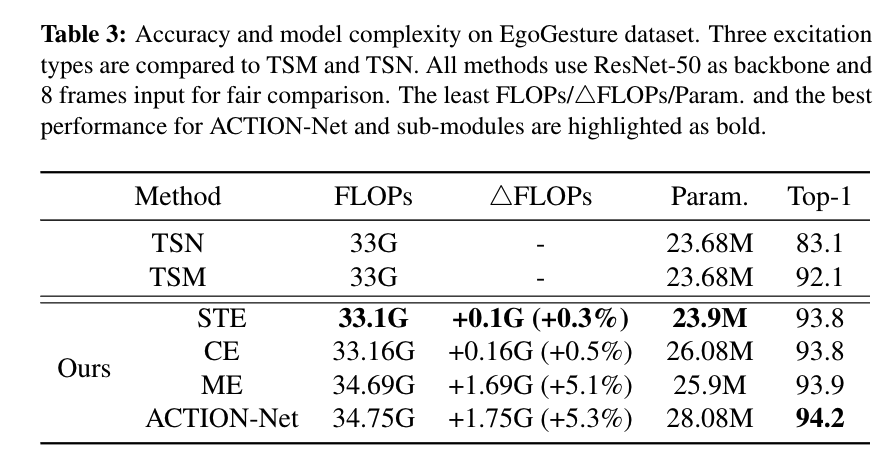
Ablation Studies
- Efficacy and induced computation of STE, CE and ME.
2. Efficacy of ACTION on different backbones.
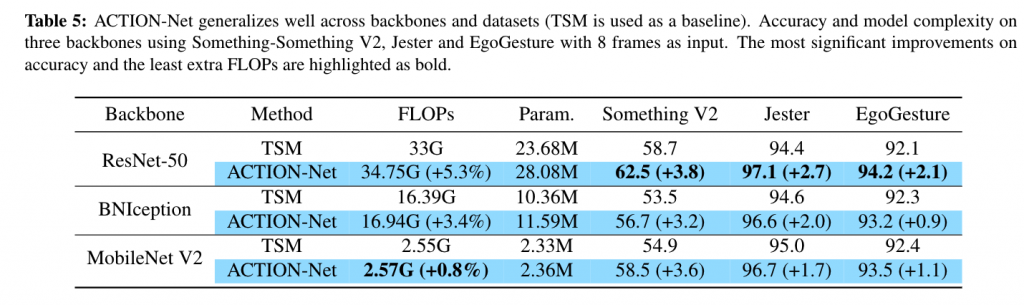
3. Efficiency of ACTION on three backbone using three datasets